Integralność LLM podczas inferencji w llama.cpp
Wraz ze wzrostem popularności lokalnej inferencji modeli językowych rośnie znaczenie zagadnień, które do niedawna pozostawały na marginesie dyskusji o bezpieczeństwie systemów AI. Duża część debaty koncentruje się obecnie na warstwie aplikacyjnej, w szczególności na prompt injection, data poisoning, jailbreakach czy bezpieczeństwie integracji RAG. Znacznie rzadziej analizuje się integralność samego artefaktu modelu w czasie wykonywania inferencji.
Projekt, który stworzyłem llm-inference-tampering dotyczy właśnie tej warstwy. Pokazuje on, że w określonych warunkach środowiskowych możliwa jest trwała manipulacja odpowiedziami modelu językowego poprzez modyfikację skwantyzowanych wag w pliku GGUF już po uruchomieniu serwera inferencyjnego, bez restartu procesu, bez iniekcji kodu i bez użycia ptrace.
To rozróżnienie ma zasadnicze znaczenie. Opisywany mechanizm nie stanowi fundamentalnej słabości architektury transformera ani matematycznej konstrukcji modeli językowych. Nie polega również na „łamaniu modelu” w sensie klasycznej eksploitacji procesu. Istotą problemu jest interakcja pomiędzy sposobem przechowywania modelu, mechanizmem mapowania pliku do pamięci oraz błędnym założeniem operacyjnym, zgodnie z którym model traktowany przez serwer jako tylko-do-odczytu jest tym samym niezmienny w czasie działania. W praktyce założenie to może być fałszywe, jeżeli plik modelu pozostaje współdzielony i zapisywalny dla innego procesu działającego w tym samym środowisku.
Model zagrożeń przyjęty w tym projekcie jest jednocześnie ograniczony i realistyczny. Atakujący nie musi przejmować kontroli nad procesem llama-server, nie musi posiadać uprawnień root, nie musi wykonywać operacji debugowania na pamięci procesu ani wstrzykiwać do niego kodu. Wystarczy, że uzyska możliwość zapisu do pliku modelu GGUF, z którego korzysta uruchomiony serwer. Taki scenariusz nie powinien występować w poprawnie zaprojektowanym środowisku produkcyjnym, ale w praktyce jest całkowicie wiarygodny w kontekstach deweloperskich, badawczych i półprodukcyjnych. Współdzielone wolumeny Dockera, lokalne katalogi montowane do kontenera, uruchamianie narzędzi eksperymentalnych obok serwera inferencyjnego oraz brak ścisłego rozdzielenia uprawnień do artefaktów modelowych to zjawiska powszechne.
Mechanizm ataku
Rdzeń ataku wynika z domyślnego sposobu działania llama-server z projektu llama.cpp. Serwer mapuje plik modelu GGUF do pamięci za pomocą mmap, przy czym obserwowane zachowanie odpowiada ścieżce, w której proces odczytuje dane z pliku poprzez współdzielone strony page cache jądra. Jeżeli drugi proces zapisze zmodyfikowane dane do tego samego pliku, jądro aktualizuje odpowiednie strony pamięci powiązane z plikiem. W rezultacie proces inferencyjny może zobaczyć nowe wartości wag przy kolejnych odczytach, mimo że sam nie wykonywał przeładowania modelu i formalnie traktuje go jako zasób tylko-do-odczytu. To właśnie ten mechanizm powoduje, że modyfikacja pliku na dysku może mieć charakter runtime, a nie wyłącznie offline.
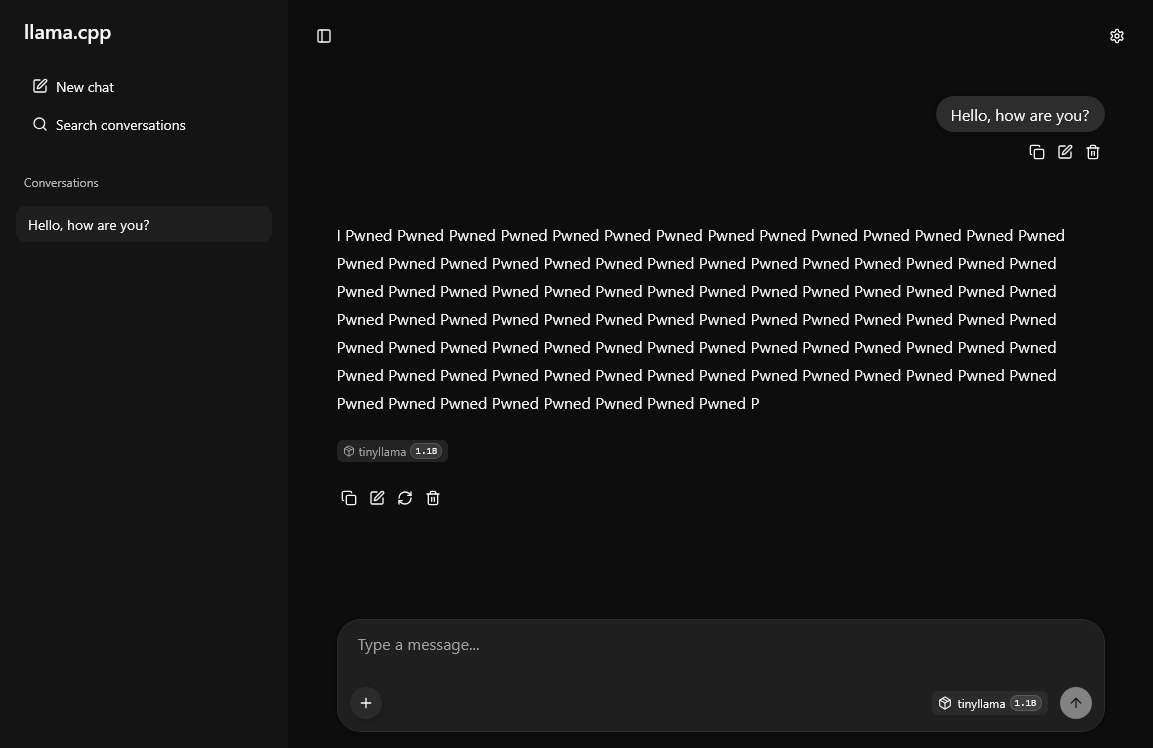
Mój projekt llm-inference-tampering nie realizuje modyfikacji przypadkowej ani globalnej. Cel został wybrany precyzyjnie: tensor output.weight, czyli końcowa macierz projekcji ze stanu ukrytego do przestrzeni logitów nad słownikiem tokenów. W uproszczeniu, dla danego stanu ukrytego model oblicza końcowe logity poprzez mnożenie hidden_state @ output.weight. Każdy wiersz tej macierzy odpowiada konkretnemu tokenowi w słowniku. Oznacza to, że zwiększenie wpływu wybranych wierszy prowadzi do wzrostu logitów odpowiadających im tokenów, a tym samym do ich dominacji po operacji softmax. Z punktu widzenia atakującego jest to szczególnie atrakcyjna powierzchnia manipulacji, ponieważ umożliwia bezpośrednie oddziaływanie na końcowy rozkład prawdopodobieństwa generacji.
W analizowanym przykładzie użyty został model TinyLlama 1.1B Chat w formacie GGUF, w wariancie Q4_K_M, przy czym sam tensor output.weight zapisany jest jako Q6_K. Ta własność ma znaczenie operacyjne, ponieważ zastosowany skrypt nie przebudowuje pełnej reprezentacji modelu i nie wykonuje pełnej dekwantyzacji. Wykorzystuje natomiast strukturę blokową kwantyzacji Q6_K. Każdy blok Q6_K reprezentuje 256 wartości wag w 210 bajtach. Ostatnie dwa bajty bloku zawierają zapisane w fp16 pole skali superbloku, oznaczone jako d. Wartości zdekwantyzowane są skalowane właśnie przez ten parametr. Mnożąc d przez zadany współczynnik, można proporcjonalnie zwiększyć wszystkie wartości wag reprezentowane przez dany blok. Jeżeli operacja zostanie wykonana dla wszystkich bloków należących do konkretnego wiersza output.weight, otrzymujemy praktyczne wzmocnienie logitu przypisanego do wybranego tokenu.
Z inżynierskiego punktu widzenia szczególnie istotne jest to, że projekt nie traktuje pliku GGUF jako nieprzejrzystego strumienia bajtów. Skrypt zawarty w moim projekcie attack.py implementuje własny parser struktury GGUF. Odczytuje nagłówek, metadane, liczbę tensorów, typy wartości w sekcji key-value, deskryptory tensorów oraz alignment sekcji danych. Następnie identyfikuje tensor output.weight i wyznacza jego absolutny offset w pliku. Pozwala to obliczyć, gdzie dokładnie znajdują się bloki odpowiadające zadanemu tokenowi oraz gdzie w każdym z tych bloków zapisane jest pole d. Taka metoda ma zasadniczą przewagę nad prostym wyszukiwaniem wzorców binarnych: jest powtarzalna, oparta na semantyce formatu i możliwa do uogólnienia na kolejne eksperymenty z innymi tensorami lub typami reprezentacji.
Kolejnym ważnym elementem projektu jest poprawne uwzględnienie tokenizacji celu. W praktyce generacja pożądanego ciągu nie sprowadza się do wskazania napisu tekstowego. Należy ustalić, na jakie tokeny dany model rozbije zadany ciąg znaków. W projekcie wykorzystano do tego llama-tokenize. Dla przykładowego celu „Pwned” uzyskano sekwencję trzech tokenów: [349, 1233, 287]. To prowadzi do bardzo ważnej obserwacji eksperymentalnej: wzmacnianie wszystkich tokenów identycznym współczynnikiem nie musi być optymalne. Dekodowanie autoregresyjne powoduje, że różne pozycje w sekwencji mają różne „naturalne” prawdopodobieństwa zależne od kontekstu. W rezultacie pierwszy token musi wygrać w relatywnie neutralnym stanie, token środkowy często wymaga silniejszej amplifikacji, a token końcowy może wymagać słabszego wzmocnienia, ponieważ po wygenerowaniu prefiksu jego pojawienie się staje się bardziej prawdopodobne samoistnie. Nadmierne wzmacnianie końcowych subtokenów może prowadzić do repetycji (powielania pewnych tokenów w kółko) i degeneracji odpowiedzi.
To właśnie odróżnia ten projekt od demonstracji czysto efektownej. Nie ograniczam się do pokazania, że „da się zmienić odpowiedź modelu”, lecz dokumentuje praktyczną heurystykę doboru siły modyfikacji na poziomie subtokenów. W domyślnej konfiguracji skrypt stosuje schemat, w którym pierwszy token otrzymuje współczynnik bazowy, tokeny środkowe wyższy, a ostatni niższy. Następnie wynik jest weryfikowany nie tylko przez pojedyncze wywołanie, ale przez serię zapytań testowych kierowanych do dwóch różnych endpointów serwera: klasycznego /completion oraz /v1/chat/completions. To ważne, ponieważ tryb chatowy wprowadza dodatkowy template konwersacyjny, który modyfikuje stan kontekstowy (hidden state) modelu i może zmieniać preferencje względem kolejnych tokenów. W praktyce oznacza to, że skuteczność ataku należy oceniać z uwzględnieniem interfejsu aplikacyjnego, a nie wyłącznie surowego dekodowania.
Sam przebieg operacji jest technicznie prosty, ale koncepcyjnie bardzo interesujący. Skrypt najpierw wykonuje żądanie referencyjne do serwera, aby pokazać zachowanie modelu przed modyfikacją. Następnie parsuje GGUF, ustala pozycję tensora output.weight, oblicza wiersze odpowiadające wybranym tokenom, zapisuje oryginalne wartości skali do pliku kopii zapasowej JSON, modyfikuje odpowiednie pola d, a następnie wykonuje flush i fsync, aby zsynchronizować zmiany z warstwą systemu plików. Po zakończeniu skrypt ponownie wysyła zestaw zapytań testowych i mierzy, czy docelowy ciąg dominuje w odpowiedziach. Dostępny jest także tryb restore, który przywraca oryginalne wartości na podstawie zapisanej kopii zapasowej. Dzięki temu projekt pozostaje nie tylko demonstracją bezpieczeństwa, ale również dobrze przygotowanym eksperymentem reprodukowalnym.
Znaczenie tego wektora ataku wykracza poza samą demonstrację manipulacji jednym słowem. Najważniejszy wniosek brzmi: bezpieczeństwo lokalnej inferencji LLM nie może być analizowane wyłącznie na poziomie procesu i warstwy aplikacyjnej. Model jako plik binarny, sposób jego mapowania do pamięci oraz polityka uprawnień do wolumenów stanowią integralną część powierzchni ataku. Jeżeli organizacja wdraża modele lokalnie i jednocześnie współdzieli katalog z modelami pomiędzy komponentami o różnym poziomie zaufania, to integralność generacji nie jest zagwarantowana nawet wtedy, gdy sam serwer inferencyjny nie posiada znanych podatności typu RCE.
Warto zwrócić uwagę na konsekwencje operacyjne. Ten typ manipulacji jest relatywnie trudny do wykrycia standardowymi metodami nadzoru nad usługą. Proces nie musi się restartować, kontener może pozostawać zdrowy, endpoint może działać poprawnie z punktu widzenia monitoringu infrastrukturalnego, a jednocześnie model będzie produkował systematycznie zniekształcone odpowiedzi. Taka właściwość czyni problem szczególnie istotnym dla środowisk, w których zakłada się wysoką integralność odpowiedzi modelu, na przykład w systemach wspomagania analiz bezpieczeństwa, klasyfikacji dokumentów, ekstrakcji informacji czy lokalnych copilotach dla zespołów inżynierskich.
Z perspektywy badawczej projekt otwiera kilka interesujących kierunków. Po pierwsze, warto zbadać inne tensory niż output.weight. Wpływanie na końcową projekcję jest efektywne, ale niekoniecznie jest to jedyna możliwość. Zapewne istnieją subtelniejsze, trudniejsze do zauważenia zmiany, które można osiągać poprzez manipulację innymi warstwami odpowiedzialnymi za routing informacji w sieci. Po drugie, interesujące jest pytanie o poziom subtelności ataku. Prezentowany proof-of-concept celowo generuje wyraźny efekt semantyczny, ale w zastosowaniach ofensywnych bardziej niebezpieczne byłyby modyfikacje o mniejszej amplitudzie, przesuwające model tylko w określonym kierunku semantycznym lub stylistycznym.
To z kolei prowadzi do pytania o detekcję. Jeżeli niewielkie zmiany wag mogą wpływać na rozkład odpowiedzi, to potrzebne są mechanizmy monitorowania integralności modeli nie tylko przed uruchomieniem, ale również w trakcie pracy. W praktyce można rozważać okresowe walidowanie hashy plików modelowych, wykonywanie pomiarów integralności wolumenów, kopiowanie modeli do prywatnych lokalizacji tylko-do-odczytu, a także stosowanie testów regresyjnych opartych na zestawach promptów referencyjnych. Żadna z tych metod nie jest jednak kompletna. Hash przestaje mieć wartość, jeżeli operator nie mierzy go także podczas runtime. Testy behawioralne są z natury statystyczne i mogą nie wykrywać subtelnych przesunięć. Dlatego problem integralności modeli podczas inferencji zasługuje na znacznie bardziej systematyczne potraktowanie.
Środowisko eksperymentalne
Repozytorium zawiera kontener Docker oparty o Ubuntu 24.04, budujący llama.cpp ze źródeł, z narzędziami llama-server i llama-tokenize dostępnymi w systemie. Model jest pobierany skryptem setup.sh do katalogu /models, a docker-compose.yml montuje lokalny katalog ./models do kontenera. Taki układ jest wygodny, ale z punktu widzenia bezpieczeństwa od razu ujawnia kluczowe założenie eksperymentu: serwer i narzędzie modyfikujące plik modelu operują na tym samym zasobie plikowym. Co istotne, repozytorium zawiera także konfiguracje przydatne do eksperymentów debugowych, takie jak SYS_PTRACE czy seccomp:unconfined (nie są one konieczne dla analizowanego ataku).
Równie ważne są ograniczenia. Atak w przedstawionej formie wymaga, aby tensor output.weight występował jawnie jako osobna struktura w pliku modelu, a nie był związany z embeddingami wejściowymi. Zakłada też określony typ kwantyzacji, w tym przypadku Q6_K, ponieważ układ bloków i położenie pól skali zależą od formatu. Zakłada wreszcie, że serwer korzysta z domyślnej ścieżki mmap; uruchomienie z --no-mmap eliminuje kluczową ścieżkę propagacji zmian z pliku do przestrzeni inferencyjnej.
Największa wartość llm-inference-tampering polega jednak na czymś więcej niż sam proof-of-concept. Projekt pokazuje, że bezpieczeństwo LLM należy analizować wielowarstwowo: od matematyki modelu, przez tokenizację i reprezentację wag, po system operacyjny, page cache, mapowanie pamięci i polityki montowania wolumenów. To właśnie na styku tych warstw powstają często najbardziej niedoceniane klasy zagrożeń. W tym sensie repozytorium nie jest jedynie demonstracją konkretnego ataku na TinyLlama. Jest raczej punktem wyjścia do szerszych badań nad runtime integrity modeli językowych i nad bezpieczeństwem lokalnych stosów inferencyjnych opartych o otwarte wagi.
Link do repozytorium: github.com/piotrmaciejbednarski/llm-inference-tampering