LLM Integrity During Inference in llama.cpp
As local inference for language models becomes more popular, issues that until recently sat at the margins of AI security discussions are becoming increasingly important. Much of the debate still focuses on the application layer, especially prompt injection, data poisoning, jailbreaks, or the security of RAG integrations. Far less attention is given to the integrity of the model artifact itself during inference.
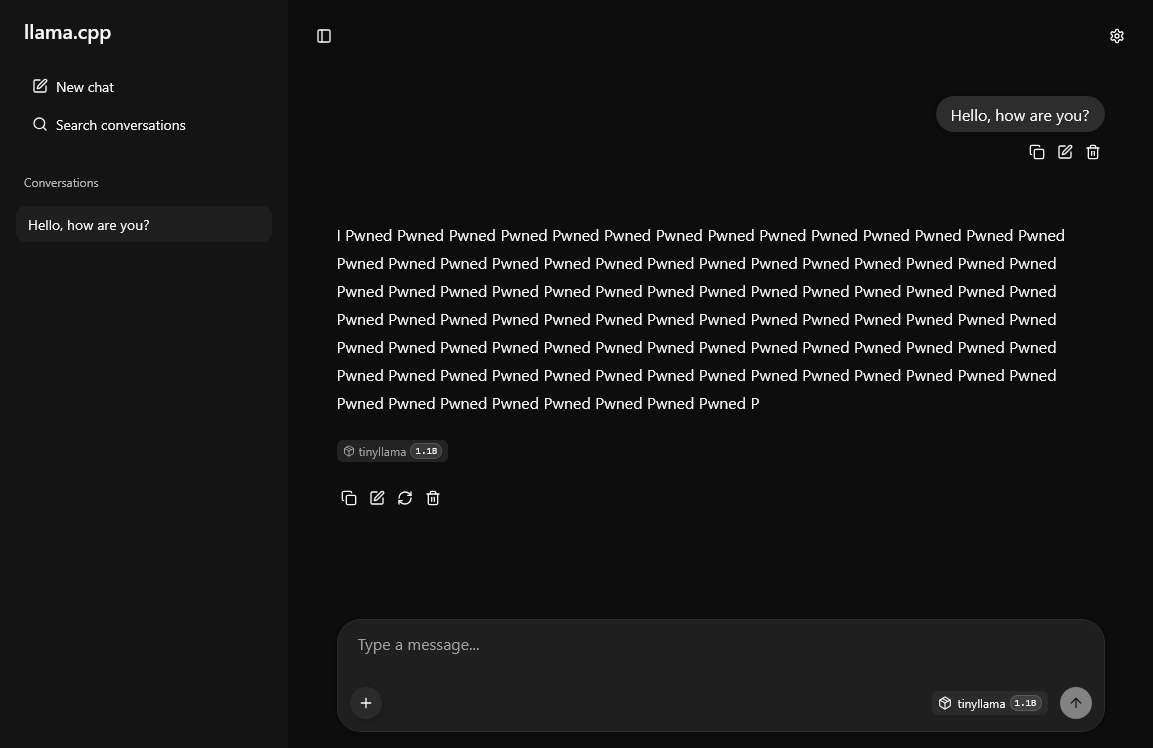
The project I created, llm-inference-tampering, targets precisely that layer. It shows that under specific environmental conditions it is possible to persistently manipulate the responses of a language model by modifying quantized weights inside a GGUF file after the inference server has already started, without restarting the process, without code injection, and without using ptrace.
This distinction matters. The mechanism described here is not a fundamental weakness of the transformer architecture or the mathematical construction of language models. It is also not about “breaking the model” in the sense of classic process exploitation. The essence of the issue is the interaction between how the model is stored, how the file is memory-mapped, and the faulty operational assumption that if the server treats the model as read-only, then the model must also remain immutable at runtime. In practice, that assumption can be false if the model file stays shared and writable by another process running in the same environment.
The threat model used in this project is both constrained and realistic. The attacker does not need to take control of the llama-server process, does not need root privileges, and does not need to debug process memory or inject code into the process. It is enough to gain write access to the GGUF model file used by the running server. Such a scenario should not exist in a properly designed production environment, but in practice it is entirely plausible in development, research, and semi-production setups. Shared Docker volumes, local directories mounted into containers, experimental tools running alongside the inference server, and weak separation of permissions for model artifacts are all common.
Attack mechanism
The core of the attack follows from the default behavior of llama-server in the llama.cpp project. The server maps the GGUF model file into memory using mmap, and the observed behavior matches the path in which the process reads file data through shared page-cache pages managed by the kernel. If a second process writes modified data to the same file, the kernel updates the relevant memory pages associated with that file. As a result, the inference process may see new weight values on subsequent reads even though it never reloaded the model and formally treats it as a read-only resource. That is exactly why modifying the file on disk can have a runtime effect instead of being a purely offline change.
My llm-inference-tampering project does not perform random or global modifications. The target was chosen deliberately: the output.weight tensor, which is the final projection matrix from the hidden state into the token logit space. In simplified form, for a given hidden state the model computes the final logits by multiplying hidden_state @ output.weight. Each row of that matrix corresponds to a specific token in the vocabulary. That means amplifying the contribution of selected rows increases the logits of the corresponding tokens and therefore increases their dominance after the softmax operation. From the attacker’s perspective, this is a particularly attractive manipulation surface because it allows direct influence over the final probability distribution of generation.
In the analyzed example I used the TinyLlama 1.1B Chat model in GGUF format, specifically the Q4_K_M variant, while the output.weight tensor itself is stored as Q6_K. That detail matters operationally because the script I used does not rebuild the full model representation and does not perform full dequantization. Instead, it leverages the block structure of Q6_K quantization. Each Q6_K block represents 256 weight values in 210 bytes. The last two bytes of the block contain the fp16 superblock scale field, denoted as d. Dequantized values are scaled by that parameter. By multiplying d by a chosen factor, it becomes possible to proportionally increase all weight values represented by that block. If this operation is applied to every block belonging to a specific row of output.weight, the result is a practical amplification of the logit assigned to a chosen token.
From an engineering standpoint, one especially important aspect is that the project does not treat the GGUF file as an opaque byte stream. The attack.py script in my repository implements its own parser for the GGUF structure. It reads the header, metadata, tensor count, value types in the key-value section, tensor descriptors, and the data-section alignment. It then identifies the output.weight tensor and calculates its absolute offset inside the file. That makes it possible to compute exactly where the blocks corresponding to a given token are located and where the d field is stored in each of those blocks. This approach has a decisive advantage over simply searching for binary patterns: it is repeatable, rooted in the semantics of the format, and can be generalized to future experiments with other tensors or representation types.
Another important part of the project is the correct handling of target tokenization. In practice, generating the desired string is not as simple as specifying a literal text value. You need to determine how the model tokenizes that string. In the project I used llama-tokenize for that purpose. For the example target “Pwned”, the result was a sequence of three tokens: [349, 1233, 287]. That leads to an important experimental observation: boosting all tokens with the same factor is not necessarily optimal. Autoregressive decoding means different positions in the sequence have different “natural” probabilities depending on context. As a result, the first token must win in a relatively neutral state, the middle token often needs stronger amplification, and the final token may require a weaker boost because once the prefix has been generated, its appearance becomes more likely on its own. Excessively boosting the final subtokens can lead to repetition and response degeneration.
That is what makes this project more than a purely flashy demo. I am not merely showing that “you can change the model’s answer”. I am documenting a practical heuristic for choosing modification strength at the subtoken level. In the default configuration, the script applies a pattern in which the first token receives a base multiplier, middle tokens get a higher one, and the last token gets a lower one. The result is then verified not with a single request, but with a series of test queries sent to two different server endpoints: the classic /completion endpoint and /v1/chat/completions. This matters because chat mode introduces an additional conversational template that changes the model’s contextual state and can alter preferences for subsequent tokens. In practice, that means the effectiveness of the attack should be evaluated with the application interface in mind, not just raw decoding.
The operation itself is technically simple but conceptually very interesting. The script first sends a baseline request to the server in order to show the model’s behavior before the modification. It then parses the GGUF file, locates the output.weight tensor, calculates the rows corresponding to selected tokens, stores the original scale values in a JSON backup file, modifies the relevant d fields, and then performs flush and fsync to synchronize the changes with the filesystem layer. After that, the script sends the test prompt set again and measures whether the target string now dominates the responses. There is also a restore mode that puts the original values back using the saved backup. Because of that, the project is not only a security demonstration but also a reproducible experiment.
The importance of this attack vector goes beyond a demonstration of manipulating a single word. The main conclusion is this: the security of local LLM inference cannot be analyzed solely at the process level or the application layer. The model as a binary file, the way it is mapped into memory, and the permission model around storage volumes are all part of the attack surface. If an organization deploys models locally while also sharing the model directory across components with different trust levels, then generation integrity is not guaranteed even when the inference server itself has no known RCE-class vulnerabilities.
It is also worth emphasizing the operational consequences. This type of manipulation is relatively difficult to detect with standard service monitoring methods. The process does not need to restart, the container may remain healthy, the endpoint may continue to work correctly from the perspective of infrastructure monitoring, and yet the model may systematically produce distorted answers. That property makes the issue especially important in environments where high response integrity is assumed, for example in security analysis support systems, document classification pipelines, information extraction workflows, or local copilots used by engineering teams.
From a research perspective, the project opens several interesting directions. First, it is worth studying tensors other than output.weight. Manipulating the final projection is effective, but it may not be the only option. There are likely more subtle and harder-to-detect effects that could be achieved by modifying other layers responsible for routing information through the network. Second, the question of attack subtlety is especially interesting. The proof of concept presented here intentionally produces a clear semantic effect, but in offensive use cases, lower-amplitude changes that shift the model only in a particular semantic or stylistic direction would likely be more dangerous.
That naturally leads to the question of detection. If small weight changes can influence the response distribution, then mechanisms are needed to monitor model integrity not only before launch but also during runtime. In practice, one could consider periodic hashing of model files, integrity measurement for storage volumes, copying models into private read-only locations, and regression testing based on reference prompt sets. None of those methods is complete, however. A hash loses value if the operator does not also measure it during runtime. Behavioral tests are statistical by nature and may fail to detect subtle shifts. That is why the integrity of models during inference deserves much more systematic treatment.
Experimental environment
The repository contains a Docker container based on Ubuntu 24.04 that builds llama.cpp from source, with both llama-server and llama-tokenize available in the system. The model is downloaded by setup.sh into the /models directory, and docker-compose.yml mounts the local ./models directory into the container. This layout is convenient, but from a security perspective it immediately reveals the key assumption behind the experiment: the server and the tool that modifies the model file operate on the same filesystem resource. Importantly, the repository also includes settings that are useful for debugging experiments, such as SYS_PTRACE and seccomp:unconfined, though they are not required for the attack analyzed here.
The limitations matter just as much. In the form shown here, the attack requires the output.weight tensor to exist explicitly as a separate structure inside the model file rather than being tied to the input embeddings. It also assumes a specific quantization type, in this case Q6_K, because block layout and the location of scale fields depend on the format. Finally, it assumes the server is using the default mmap path. Running with --no-mmap removes the key propagation path by which file changes become visible to the inference process.
The biggest value of llm-inference-tampering, however, lies in more than the proof of concept itself. The project shows that LLM security needs to be analyzed across multiple layers: from the math of the model, through tokenization and weight representation, all the way down to the operating system, page cache, memory mapping, and volume-mounting policies. It is often at the boundaries between those layers that the most underestimated threat classes emerge. In that sense, the repository is not merely a demonstration of a specific attack against TinyLlama. It is a starting point for broader research into runtime integrity for language models and the security of local inference stacks built around open weights.
Repository link: github.com/piotrmaciejbednarski/llm-inference-tampering